Week 5: Demographics #
Monday, October 7, 2024
28 Days until Presidential Election
Welcome back! This week I will focus on demographic data and the role it plays in forecasting. Since last week, the vice presidential candidates faced off in a relatively calm and respectful debate. Again, a principal topic was that of immigration, which, in addition to being incredibly polarizing, often falls to identity-based arguments and concerns over the makeup of the United States demographically. Demographic shifts in race, educational attainment, and income distribution are an undercurrent to many political debates at the community level up to the national level. How identity can affect electoral politics is an incredibly large academic theme within the field of political science. In this post, I will touch on a seminal paper by Kim and Zilinsky (2024), which contributes to the question of if demographics motivate vote choice. I will then move into analyzing the demographics of my own state and a significant battleground state: Georgia. I will end by running simulations of my own model to quantify uncertainty in my own prediction and to visualize what that final prediction looks like as of now.
Demographic Indicators and Vote Choice #
## Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
## prediction from a rank-deficient fit may be misleading
| Model 1 | |
|---|---|
| (Intercept) | 1.697 |
| (0.112) | |
| age | 0.001 |
| (0.0008) | |
| gender | −0.348 |
| (0.030) | |
| race | −0.496 |
| (0.020) | |
| educ | 0.021 |
| (0.016) | |
| income | 0.104 |
| (0.012) | |
| religion | −0.221 |
| (0.014) | |
| attend_church | −0.121 |
| (0.009) | |
| southern | −0.137 |
| (0.032) | |
| work_status | 0.065 |
| (0.013) | |
| homeowner | −0.0007 |
| (0.006) | |
| married | −0.071 |
| (0.009) | |
| Num.Obs. | 21726 |
| AIC | 27961.6 |
| BIC | 28057.4 |
| Log.Lik. | −13968.797 |
| RMSE | 0.47 |
## Confusion Matrix and Statistics
##
## Reference
## Prediction Democrat Republican
## Democrat 8082 3961
## Republican 3704 5979
##
## Accuracy : 0.6472
## 95% CI : (0.6408, 0.6536)
## No Information Rate : 0.5425
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.2878
##
## Mcnemar's Test P-Value : 0.003455
##
## Sensitivity : 0.6857
## Specificity : 0.6015
## Pos Pred Value : 0.6711
## Neg Pred Value : 0.6175
## Prevalence : 0.5425
## Detection Rate : 0.3720
## Detection Prevalence : 0.5543
## Balanced Accuracy : 0.6436
##
## 'Positive' Class : Democrat
##
## Warning in predict.lm(object, newdata, se.fit, scale = 1, type = if (type == :
## prediction from a rank-deficient fit may be misleading
## Confusion Matrix and Statistics
##
## Reference
## Prediction Democrat Republican
## Democrat 1973 975
## Republican 973 1509
##
## Accuracy : 0.6413
## 95% CI : (0.6283, 0.654)
## No Information Rate : 0.5425
## P-Value [Acc > NIR] : <2e-16
##
## Kappa : 0.2772
##
## Mcnemar's Test P-Value : 0.9819
##
## Sensitivity : 0.6697
## Specificity : 0.6075
## Pos Pred Value : 0.6693
## Neg Pred Value : 0.6080
## Prevalence : 0.5425
## Detection Rate : 0.3634
## Detection Prevalence : 0.5429
## Balanced Accuracy : 0.6386
##
## 'Positive' Class : Democrat
##
The above figures are a result of using a logistic regression that involves demographics to predict presidential vote choice. Much of this code can be attributed to Matthew Dardet, but instead of just looking at how well demographics predicted vote choice in 1964, I included all years including and thereafter. The demographics we involve are age, gender, race, education level, income, religion, whether the voter attends church, whether the voter is from a southern state, work status, home-owning status, and marriage status. The model summary above shows that gender and race have by far the most sway on a voter’s choice among these demographics. What I find interesting is that age does not really have that much of an impact on vote choice as compared to other demographics. This work is a replication of the original work of Kim and Zilinsky (2024). Similar to their paper’s most notable finding, this replication finds that these key demographics can only predict the vote choice accurately about 64% of the time. Given the reliance of popular media and conventional wisdom on identity politics, it would seem that demographics would play a huge role in vote choice, and they are certainly not negligible. But key demographics are not as determinative as we might have thought.
## Confusion Matrix and Statistics
##
## Reference
## Prediction Democrat Republican
## Democrat 7926 3091
## Republican 3860 6849
##
## Accuracy : 0.6801
## 95% CI : (0.6738, 0.6863)
## No Information Rate : 0.5425
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.3593
##
## Mcnemar's Test P-Value : < 2.2e-16
##
## Sensitivity : 0.6725
## Specificity : 0.6890
## Pos Pred Value : 0.7194
## Neg Pred Value : 0.6396
## Prevalence : 0.5425
## Detection Rate : 0.3648
## Detection Prevalence : 0.5071
## Balanced Accuracy : 0.6808
##
## 'Positive' Class : Democrat
##
## Confusion Matrix and Statistics
##
## Reference
## Prediction Democrat Republican
## Democrat 1951 728
## Republican 995 1756
##
## Accuracy : 0.6827
## 95% CI : (0.6701, 0.6951)
## No Information Rate : 0.5425
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.3661
##
## Mcnemar's Test P-Value : 1.472e-10
##
## Sensitivity : 0.6623
## Specificity : 0.7069
## Pos Pred Value : 0.7283
## Neg Pred Value : 0.6383
## Prevalence : 0.5425
## Detection Rate : 0.3593
## Detection Prevalence : 0.4934
## Balanced Accuracy : 0.6846
##
## 'Positive' Class : Democrat
##
Here, instead of relying on a logistic regression, we employ a Random Forests model. Random Forest modeling is a type of machine learning model where multiple decision trees are built for training and their predictions are aggregated in such a way that is advantageous for accuracy and the reduction of overfitting. Because we are involving so many demographic indicators, it would be useful to use Random Forest modeling and be aware of the risk of overfitting. When we use Random Forests to replicate Kim and Zilinsky’s (2024) work, we find that the key demographics can only predict vote choice about 68% of the time. This is a few percentage points higher than when we relied on the logistic regression, but it is not fully determinative, underscoring Kim and Zilinsky’s findings as well.
| Party | Predicted Vote Share (%) |
|---|---|
| Democrat | 50.46 |
| Republican | 49.54 |
I use the Random Forest modeling, which at its crux relies on bootstrap sampling, to predict national vote share based on demographics, including ideology identification metrics. It finds that the Democrats will just narrowly win the popular vote in November. This falls in line with previous models and current polls about the election being one of the closest in decades.
Delving into a State Voter File #
Now, let’s delve into a sample of Georgia’s voter file. I chose Georgia because it is my home state, I have done political mobilizing on the ground there, and I have been closely following it this election. The voter file data we are relying on is a sample of 1% of the total voter file data for the Georgia electoral and has been generously provided by Statara Solutions. Please check them out here.
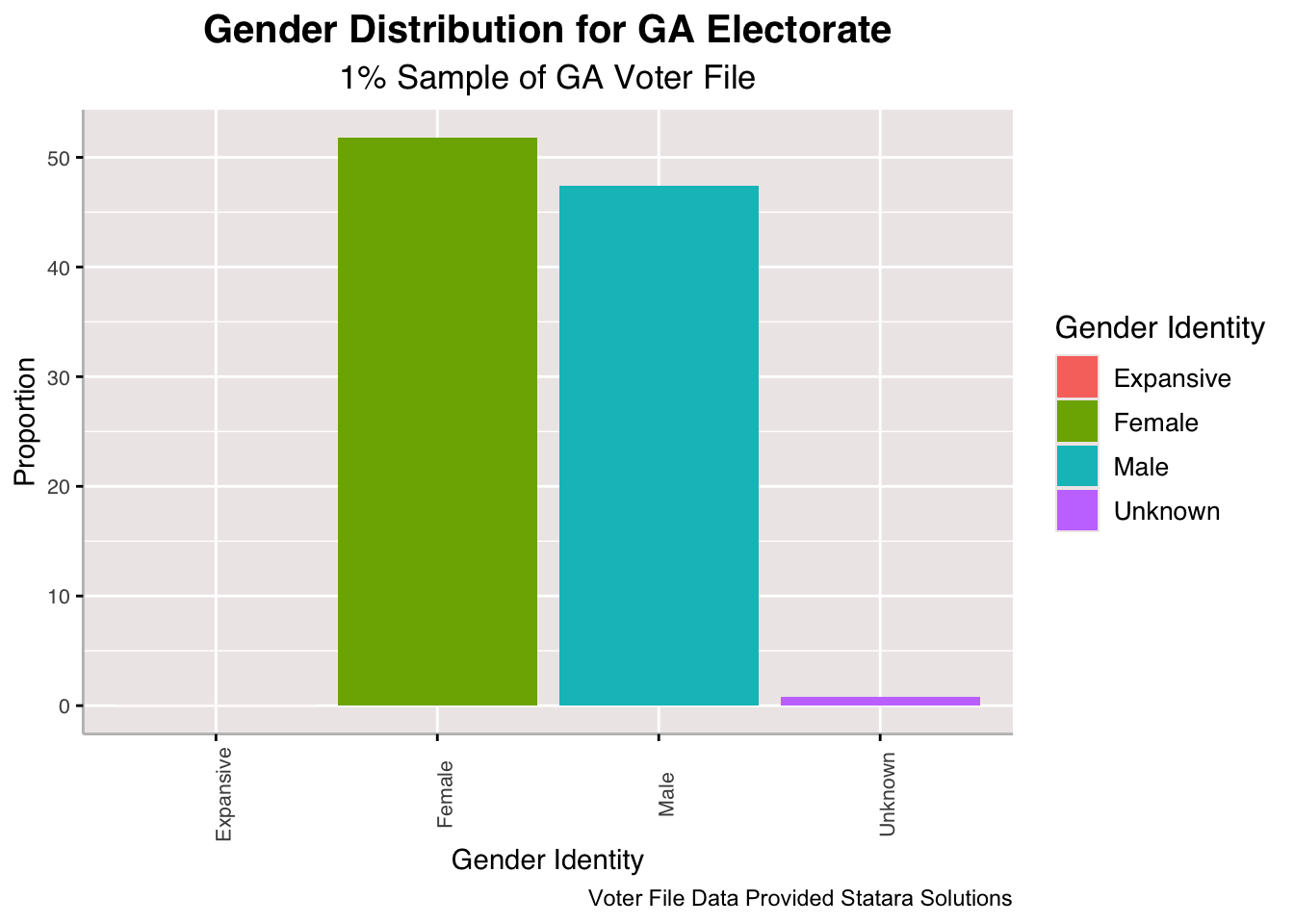
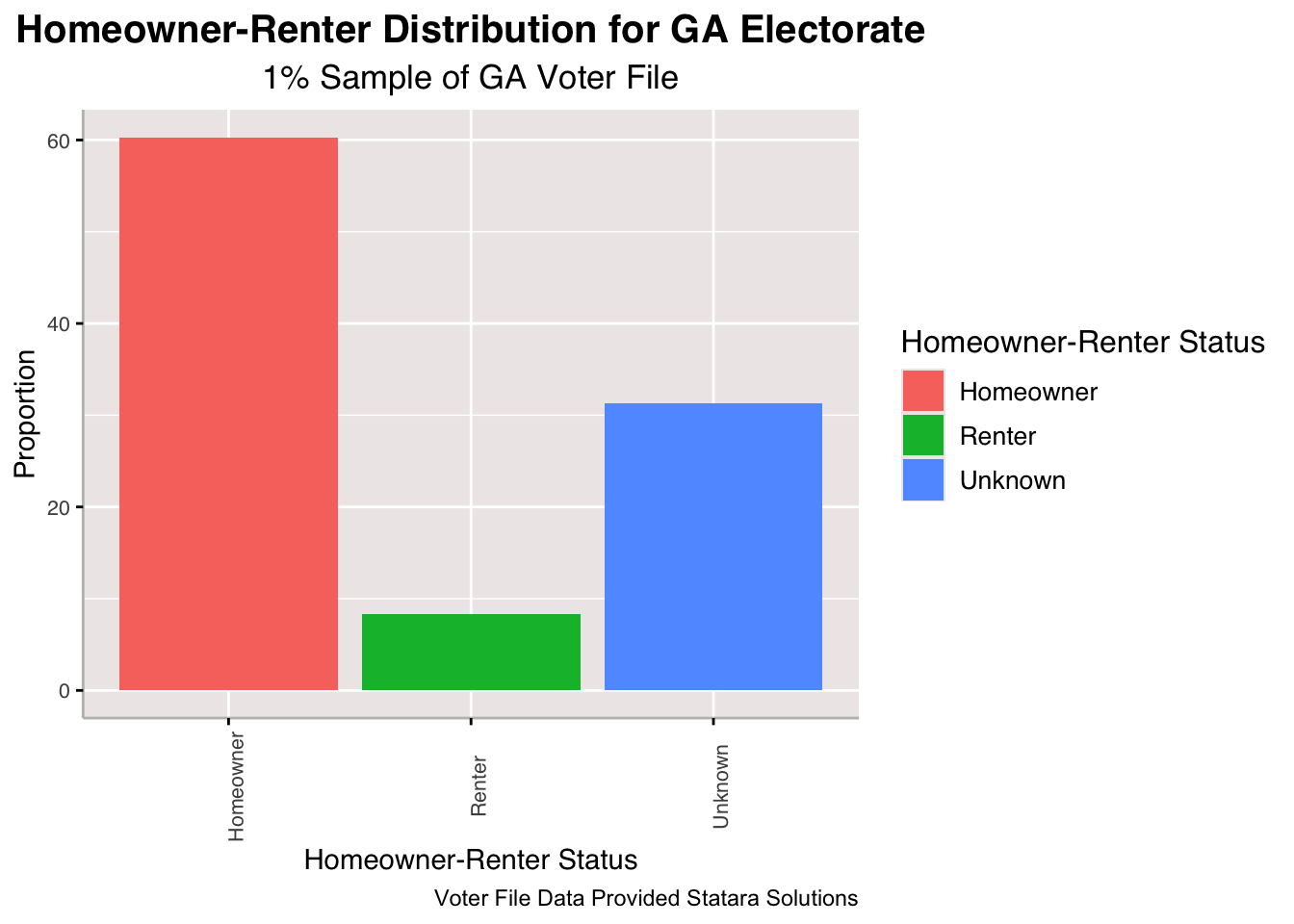
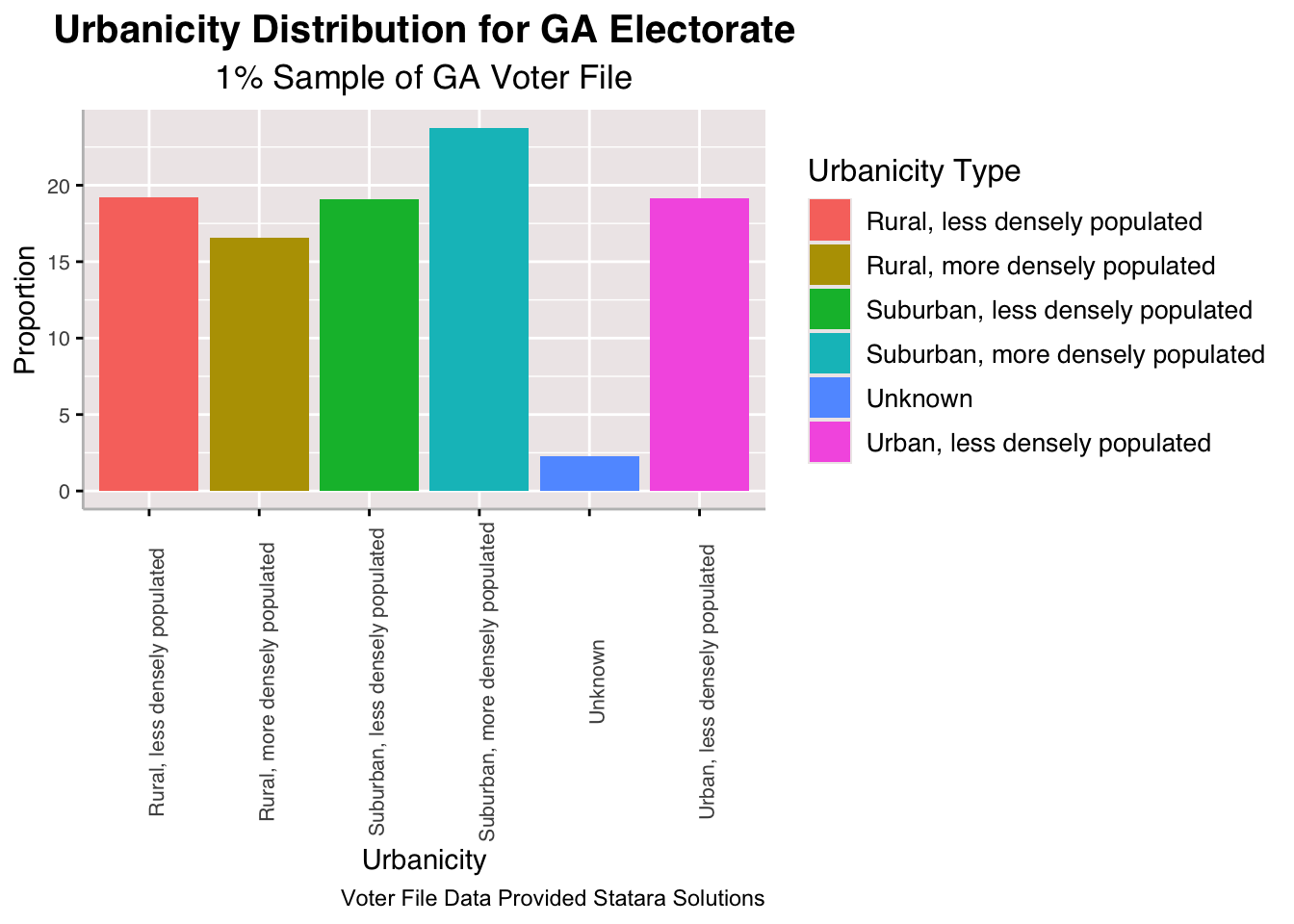
Above, we look at five key demographics indicators and how they are distributed for the Georgia electorate. First, we see that the gender distribution is relatively similar among males and females in the state with slightly more females. The population of those pertaining to expansive gender identities is very few and among this sample only 8 actually do identify as such.
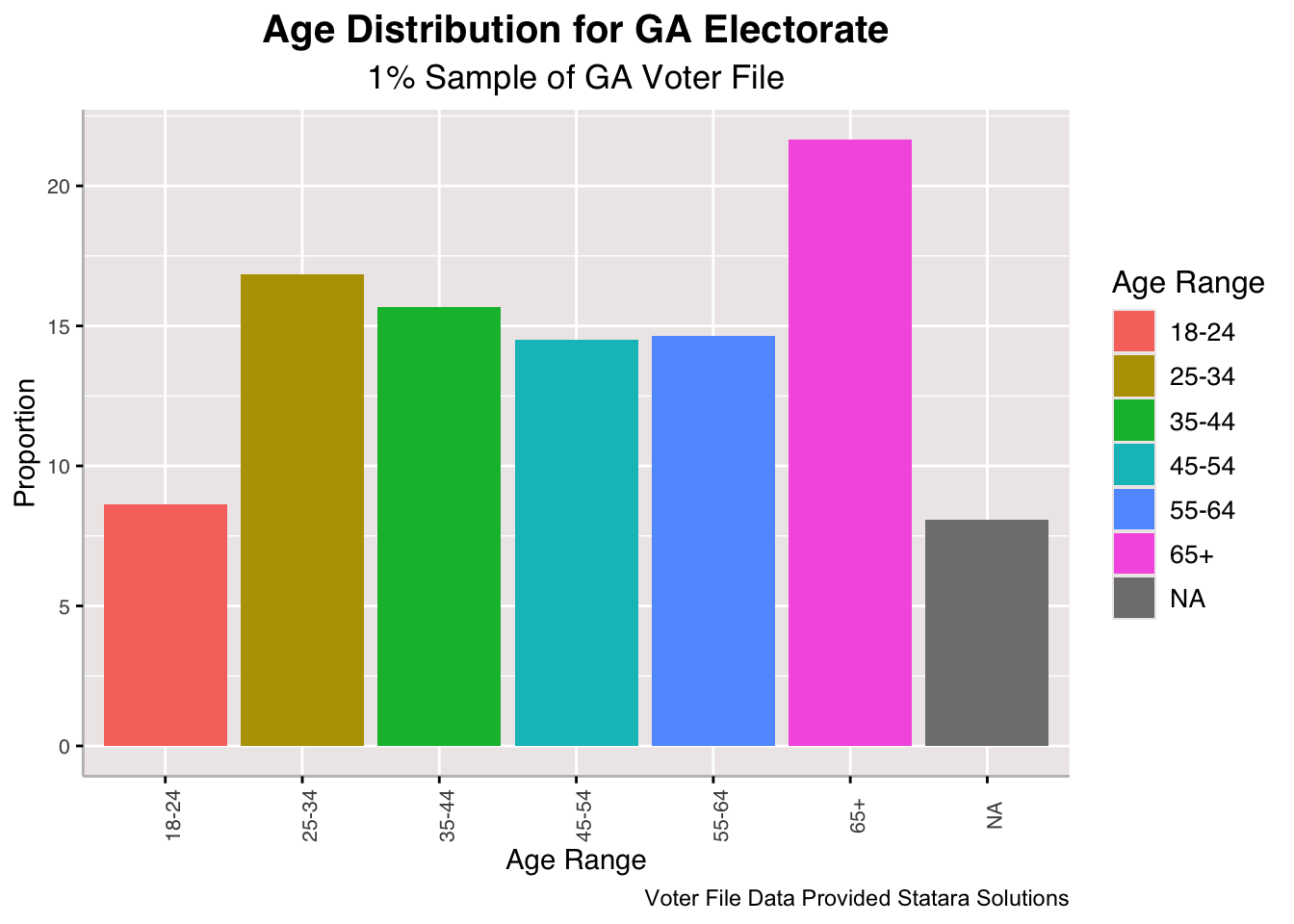
The age distribution for various ranges is even, except for 18-24 year olds and 65+. This makes sense because the range of ages for 18-24 is fewer than other buckets and there are a large amount of ages for which the 65+ bucket covers. Remember this was an indicator that, according to Kim and Zilinsky’s (2024) finding, did not affect vote choice all that much.
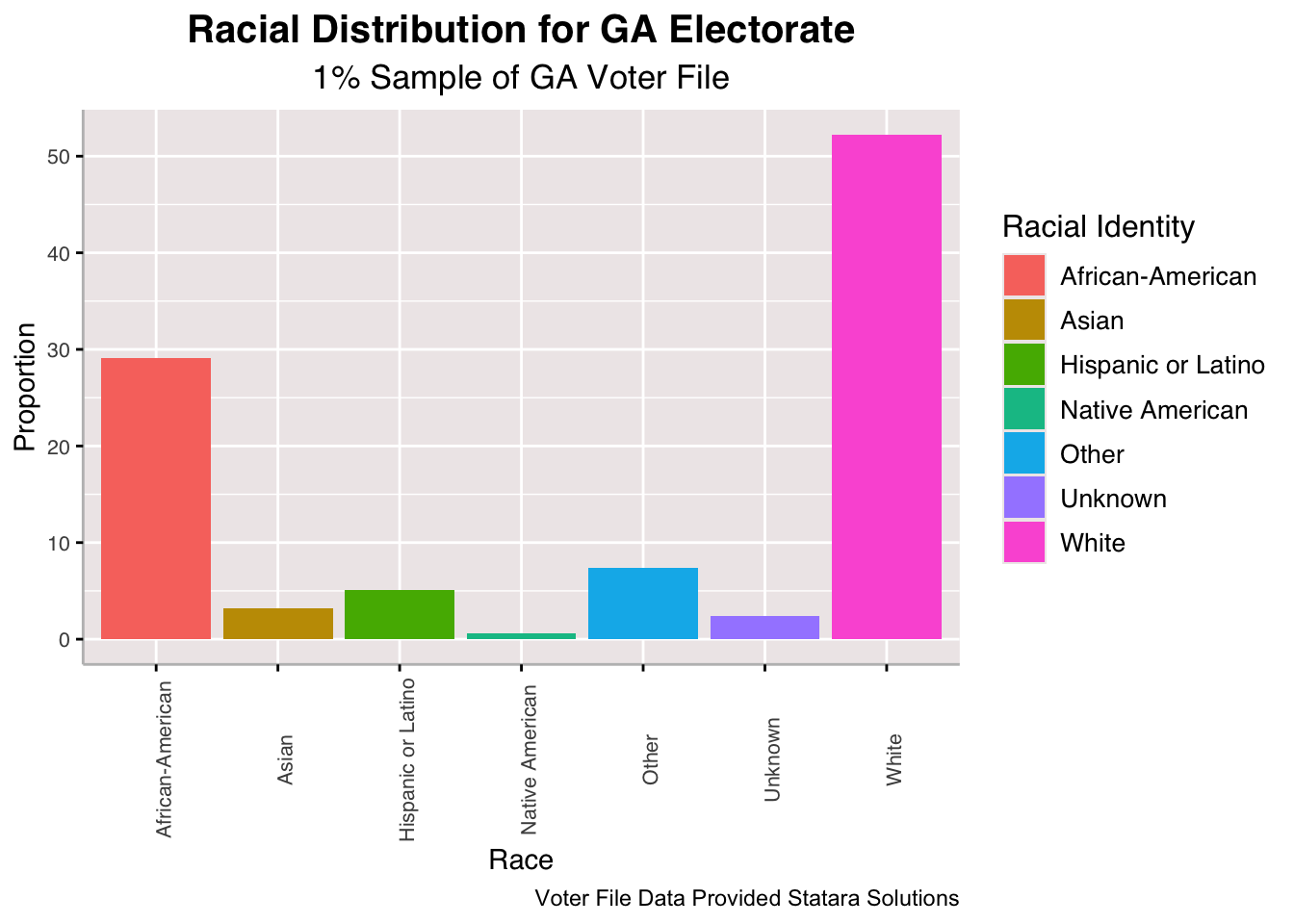
Despite the national trend toward the minority majority phenomenon, Georgia’s electorate is still majority white. It also has a large Black population and sizable Asian and Hispanic/Latino populations. The indigenous population among Georgia’s electorate is quite low, especially compared to other states like Hawaii and Alaska.
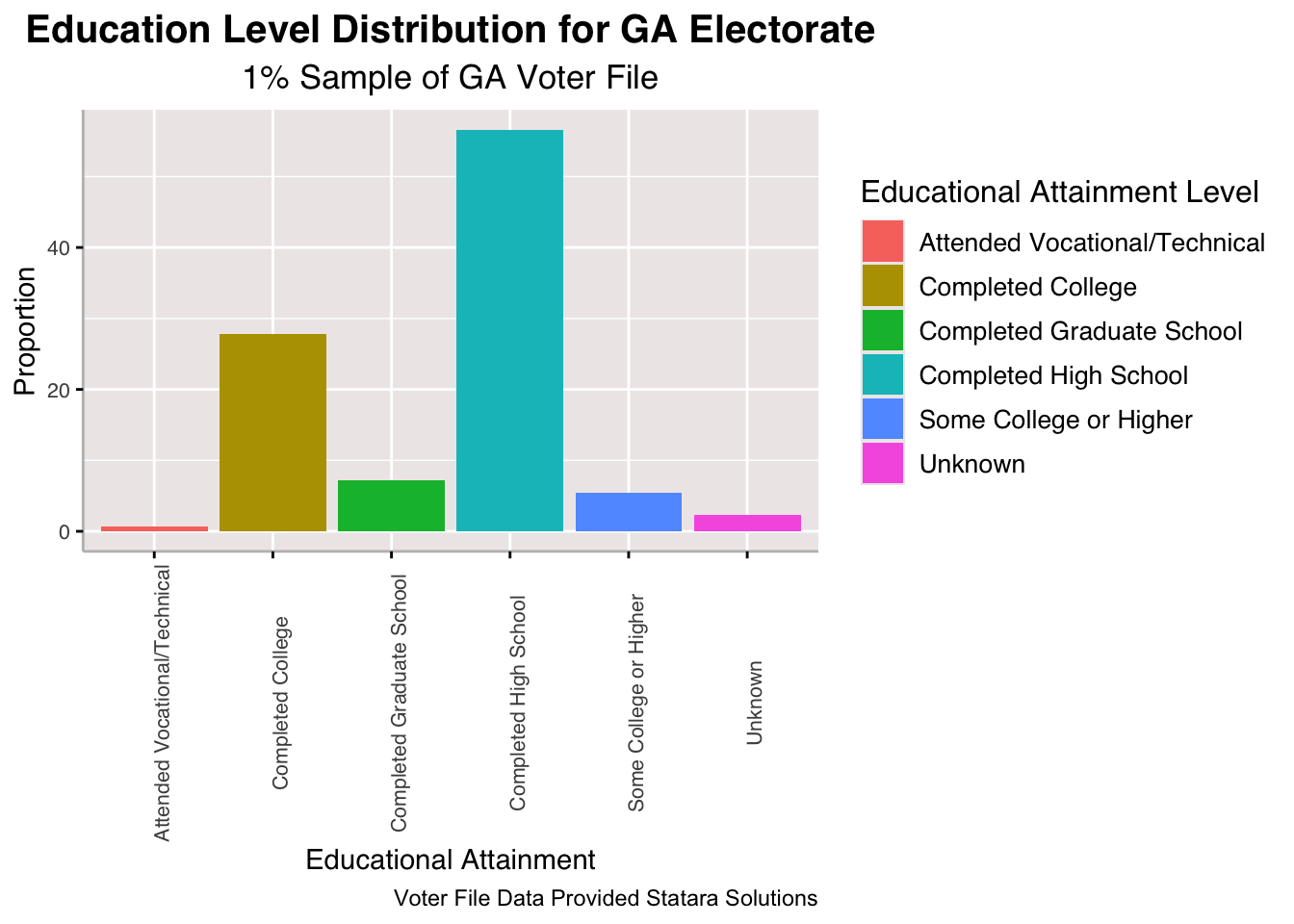
As for education attainment, the plurality of Georgia’s electorate completed high school and a relatively large portion completed college. I did not expect that more Georgian voters completed graduate school than just some college or higher.
Because this data was available, I was curious to see the distribution of homeowners versus renters among Georgian voters. I was surprised to see that most voters are actually homeowners, according to this sample.
Lastly, Georgia has one very large metropolitan city with urban sprawl, Atlanta, and a lot of other small to mid size cities. It also has a large rural populations. This even distribution is reflected in the urbanicity graph.
Model Simulations for Battleground States #
## `summarise()` has grouped output by 'state'. You can override using the
## `.groups` argument.
| State | Democrat | Republican |
|---|---|---|
| Arizona | 0.0006 | 0.9994 |
| Georgia | 0.9116 | 0.0884 |
| Michigan | 1.0000 | 0.0000 |
| Nevada | 1.0000 | 0.0000 |
| North Carolina | 0.9755 | 0.0245 |
| Pennsylvania | 1.0000 | 0.0000 |
| Wisconsin | 1.0000 | 0.0000 |
| State | mean_dem | mean_rep | sd_dem | sd_rep | lower_dem | upper_dem | lower_rep | upper_rep |
|---|---|---|---|---|---|---|---|---|
| Arizona | 52.25068 | 53.01345 | 0.1576075 | 0.3662173 | 51.94177 | 52.55959 | 52.29567 | 53.73124 |
| Georgia | 52.57779 | 52.29352 | 0.1605107 | 0.3729632 | 52.26319 | 52.89239 | 51.56251 | 53.02452 |
| Michigan | 53.61763 | 50.50728 | 0.1603770 | 0.3726526 | 53.30329 | 53.93197 | 49.77688 | 51.23768 |
| Nevada | 54.10442 | 52.23273 | 0.1599942 | 0.3717632 | 53.79083 | 54.41801 | 51.50407 | 52.96138 |
| North Carolina | 52.60621 | 52.20061 | 0.1577668 | 0.3665874 | 52.29699 | 52.91543 | 51.48210 | 52.91912 |
| Pennsylvania | 52.87369 | 51.60073 | 0.1587398 | 0.3688483 | 52.56256 | 53.18482 | 50.87779 | 52.32368 |
| Wisconsin | 53.30806 | 51.05413 | 0.1592734 | 0.3700883 | 52.99589 | 53.62024 | 50.32875 | 51.77950 |
Here, I simulate the 2024 election for key battleground states: Georgia, Michigan, Nevada, Wisconsin, North Carolina, Arizona, and Pennsylvania. I involve Democratic and Republican vote shares for the past two elections, Democratic and Republican polling averages for this election, voter turnout, and economic indicators in the form of the Consumer Price Index and the quarterly GDP growth. This is an expansion of my model from past weeks because I now involve voter turnout data.
Popular poll aggregators and forecasters, like FiveThirtyEight and the Silver Bulletin, use simulations to quantify the uncertainty of their models. Most recently, simulation of FiveThirtyEight’s model has demonstrated a virtual coin flip outcome, or a 53 in 100 chance of Harris winning the electoral college and 47 in 100 change of Trump winning the electoral college.
It appears that all cases the sum of the mean two party vote share for Democrats and Republicans in the same state is more than 100%. We can attribute this to the fact that these models independently and linearly (without an imposed bound) predict for vote shares between Republicans and Democrats. In 6 out of the 7 battleground states, Democrats are projected to win. The one state where Republicans win is Arizona, which would be a flip back to a Trump victory after Biden won the state in 2020. It is critical to note that for all these predictions, the winning vote shares are well within the margins of error and each party realistically has a chance to win. This is not reflected looking just at how the simulation attributes wins to each party, for example, saying that Democrats win Nevada in 100% of all simulations. When more variables are involved in the simulation, particularly racial demographic changes and respective voter turnouts among racial groups, I predict that this would be much closer across all simulations.
| D | R |
|---|---|
| 305 | 233 |
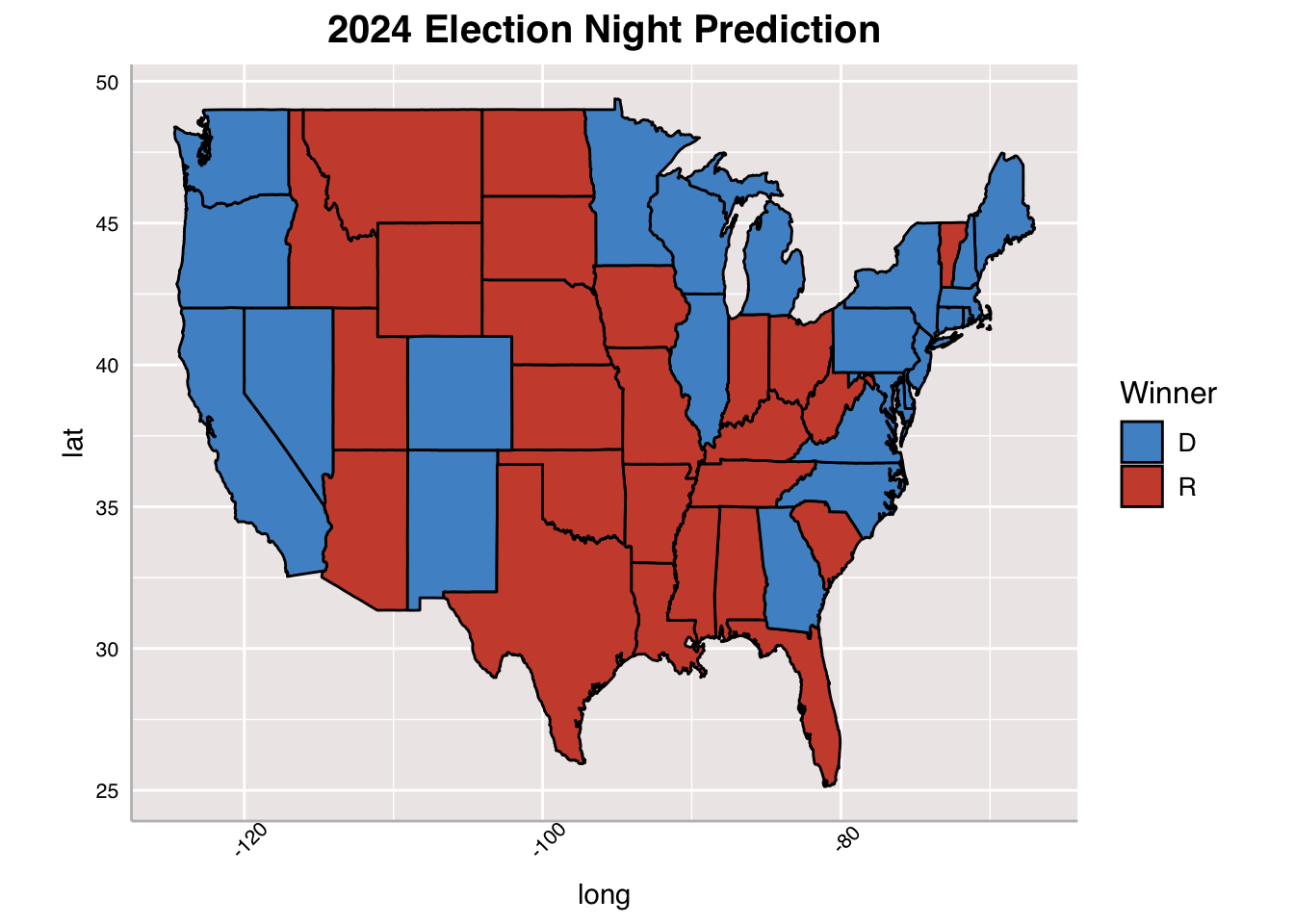
Here is the map I predict to see on Election Night this November, according to my model this week. I predict that Harris will win the electoral college and clear the 270 threshold, as per my simulations that involve voter turnout and economic indicators as well as polling data and past vote shares. In all honesty, though, I think the race will be much closer than this, and I hope in future weeks to reflect that.
Conclusion #
According to this week’s models, Harris will win the 2024 Presidential Election, taking 305 electoral votes.
I myself am skeptical of this finding because it does not fall in line with the conventional wisdom about the closeness of this race. It also does not comport well with the incredibly close national popular vote share that I calculated using the Random Forests model based on demographics. I find it hard to believe a possibility where Harris would barely win over Trump in the popular vote by less than a percentage point but also take 6 of the 7 critical battleground states. In future models, I hope to reflect the competitiveness of this race better.
Sources #
“2024 Election Forecast.” FiveThirtyEight, 2024, https://projects.fivethirtyeight.com/2024-election-forecast/.
Seo-young Silvia Kim and Jan Zilinsky. Division does not imply predictability: Demographics continue to reveal little about voting and partisanship. Political Behavior, 46(1):67–87, March 2024. ISSN 1573-6687. doi: 10.1007/s11109-022-09816-z.
Polling Data Provided by GOV 1347: Election Analytics teaching staff (which itself drew from the FiveThirtyEight GitHub)
Economic Data Provided by GOV 1347: Election Analytics teaching staff (which itself drew from the Burueau of Economic Analysia and Federal Reserve Economic Data)
Demographic Data Provided by GOV 1347: Election Analytics teaching staff (which itself drew from the Burueau of Economic Analysia and Federal Reserve Economic Data)
Voter File Data Provided by Statara Solutions. Check them out here: https://statara.com/.